개인정보위, 생성형 AI 개발·활용 '개인정보 처리 기준' 공개


- 생성형 AI 개발·활용 위한 개인정보 처리 기준 제시
- 생애주기 4단계 나눠 안전조치 제시…최신기술 동향·연구성과 등 반영
생성형 인공지능(AI) 개인정보 안전 처리 기준이 발표됐다. 개인정보보호위원회는 6일 서울 중구 정동 1928 아트센터에서 개최한 ‘생성형 인공지능과 프라이버시’ 오픈 세미나에서 안내서가 챗GPT 등 상용 대규모언어모델(LLM) 서비스뿐만 아니라, 라마(Llama) 등 오픈소스 LLM을 활용한 서비스 개발 기업에도 적용 가능하다고 밝혔다.
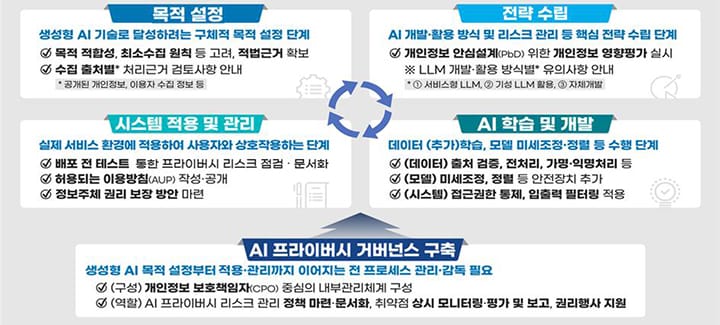
① 생성형 AI 개인정보 처리 기준 첫 제정…불확실성 해소 기대
그간 생성형 AI 현장에선 개인정보보호법 적용의 불확실성과 실무 혼선을 해소할 체계적 기준 마련 요구가 꾸준히 제기돼 왔다. 개인정보위는 다양한 민간·전문가 의견수렴과 정책협의회를 거쳐 실질적 가이드라인을 마련, 현장 실무자들이 법적 불확실성을 해소할 기반이 될 것으로 기대하고 있다.
② AI 개발 전 생애주기별 단계적 안전조치·관리 지침 제시
안내서는 생성형 AI 개발 및 활용 전 과정을 △목적 설정 △전략 수립 △학습·개발 △적용·관리의 4단계로 구분하고 각 단계별 최소한의 안전조치를 구체적으로 제시했다. 목적 설정 단계에서는 인공지능 개발 목적의 명확화와 개인정보 종류·출처별 적법 근거 확보를 강조하고, 전략 수립단계는 개발 방식별 리스크 평가 및 대응 방안을 안내한다. 학습 및 개발 단계에서는 데이터 오염, 모델 탈옥 등 다양한 리스크에 대비한 다층적 안전장치를 제시하며, 적용 및 관리 단계에서는 정보주체(이용자)의 권리 보장에 초점을 맞췄다. 또한 개인정보보호책임자(CPO) 중심의 거버넌스 구축을 권고하며, 반복적 개선 과정을 거쳐 시스템 고도화를 지향한다는 내용도 담았다.
③ 정책·집행 사례 토대로 AI 개인정보 쟁점 구체적 해법 마련
개인정보위는 개인정보의 AI 학습 활용 법적 기준 등 쟁점에 대해 정책 및 집행 경험을 바탕으로 구체적 해결방안을 안내서에 반영했다. 기존에 준비된 안내자료, 사전실태점검, 규제샌드박스 및 적정성 검토 등 다양한 경험을 통해 현장에 유의미한 사례 중심의 해법을 제시했다. 개인정보위 고학수 위원장은 “명확한 안내서로 실무 현장의 법적 불확실성이 해소될 것으로 기대되며, 앞으로도 프라이버시와 혁신, 두 가치가 조화를 이루도록 정책적 노력을 이어갈 것”이라며 지속적 안내서 개선 의지를 밝혔다.
Related Materials
- AI Agents Are Advancing—But Enterprise Data Privacy and Security ... - Cloudera, 2025년
- What the International AI Safety Report 2025 has to say ... - Private AI, 2025년
- AI Privacy Risks & Mitigations – Large Language Models (LLMs) - European Data Protection Board, 2025년
- Minding Mindful Machines: AI Agents and Data Protection Considerations - FPF, 2025년






