구글의 인공지능 버그 사냥꾼, 최초 보고서까지 발행


- 구글의 빅슬립, 20개 취약점 발견해 보고서 작성 완료
- "자동화 취약점 탐지 및 보고의 시대 열렸다"
- 아직 인공지능 취약점 탐지 기술 완벽하지 않아
구글의 ‘인공지능 버그 헌터’가 처음으로 보안 취약점 보고서를 발표했다. 인간의 개입이 최소화 된 상태에서 대형 언어 모델(LLM) 기반 인공지능 도구가 스스로 취약점들을 찾아내, 인간이 알아볼 수 있는 수준의 보고서 생성까지 한 것이다. 보안 업계에 새로운 전기가 마련될 수도 있을 만한 일로 평가되고 있다.
이 인공지능 모델의 이름은 빅슬립(Big Sleep)이다. 여러 인기 오픈소스 소프트웨어에서 20개의 보안 취약점을 발견해냈다. 하지만 FFmpeg와 이미지 편집 도구에 영향을 주는 소프트웨어들이라는 것 외에는 공개된 것이 없다. 구글은 원래 취약점에 대해 세상에 알릴 때 세부 기술 정보를 곧바로 공개하지 않는 편이다. 패치가 나오고 충분한 시일이 지나 사용자들이 보편적으로 업데이트를 진행했다고 판단되는 시점까지 기다린다. 빅슬립의 성과를 세부적으로 공개하지 않는 것도 같은 맥락에서다.
인간 개입 최소화
정말 인간 개입이 하나도 없었을까? 취약점 분석, 판별, 보고서 b작성까지 전부 자동으로 이뤄진 것일까? 구글 측은 “사실상 그렇다”고 말한다. “빅슬립이 찾아낸 취약점을 인간 분석가가 검증하고, 빅슬립이 작성한 보고서도 인간 분석가가 마지막에 확인했습니다. 하지만 그 중간 과정들에는 인간 개입이 없었습니다. 실제 일은 인공지능이 혼자 다 하고, 인간은 신뢰성을 높이기 위해 마지막 확인만 한 것입니다.”
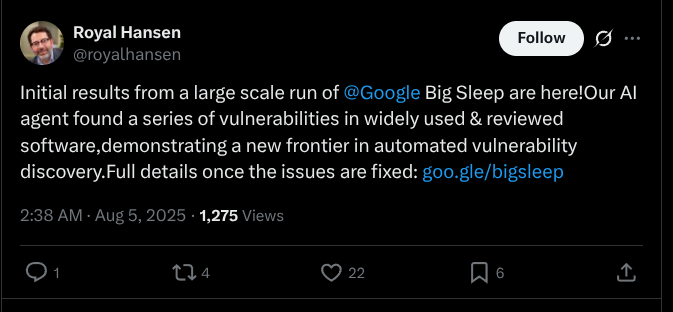
이 때문에 일각에서는 “자동화 된 취약점 탐지 및 분석의 장을 열었다”고까지 표현한다. 구글의 엔지니어링 부사장 로얄 한센(Royal Hansen)이 대표적인 인물이다. 그는 엑스를 통해 구글의 성과를 치켜올리면 그와 같은 문구를 올렸다.
다만 취약점 연구와 분석, 탐지를 전문으로 하는 인공지능 모델이 이번에 처음 나온 건 아니다. 빅슬립 이전에도 런시빌(RunSybil)이나 엑스보우(XBOW) 등이 존재했다고 테크트런치 등 IT 외신들은 지적한다. “특히 엑스보우의 경우 버그바운티 플랫폼인 해커원(HackerOne)에서 1위에 오르기도 했습니다. 엑스보우의 경우도 인공지능이 취약점을 탐지하면 인간이 그것을 확인하는 식으로 일을 진행합니다.”
하지만 일각에서는 불만이 나오고 있기도 하다. 인공지능이 생성한 취약점 보고서 내용 중 허상(혹은 환각)으로 보이는 것들이 있다는 내용이 이전부터 제기되었던 것이다. 수많은 취약점 분석 보고서를 검토하여 상금까지 정하여 수여해야 하는 입장에서는, 이러한 보고서의 존재 자체가 업무에 큰 차질을 준다고 한다. “아직 인공지능이 만들어낸 보고서라는 걸 신뢰하기는 힘듭니다. 인공지능 취약점 탐지 모델들은 스스로를 좀 더 증명해야 할 것입니다.”
빅슬립, 엑스보우, 런시빌의 핵심 성과
현존하는 인공지능 취약점 탐지 모델들이 보여준 가장 큰 성과는 무엇이었을까? 한센 구글 부사장이 말한 것처럼 ‘자동화 기술로도 취약점을 탐지해 분석할 수 있다’는 걸 증명한 것? 인간의 개입을 최소화 하고도 쓸모 있는 보고서가 탄생한다는 것? 아니다. 오히려 인간의 검증과 확인 단계가 취약점 분석부터 보고서 작성에 이르기까지 존재했다는 것이라고 IT 외신 데이터코노미는 짚는다.
일부 오픈소스 메인테이너들은 인공지능이 만든 버그 리포트 중 품질이 엉망인 것을 두고 ‘인공지능 슬롭(AI Slop)’이라고 부르기도 한다. ‘인공지능 슬롭’이란, 인공지능으로 생성한 콘텐츠들 중 품질이 낮은 것들의 멸칭이다. 보안 분석가 혹은 패치 개발자들 입장에서는 잘못된 보고서에 시간과 노력을 들이는 것이 무척 아까운(발견되는 취약점 수가 절대적으로 많아서) 일인데, 인공지능 모델들이 제공하는 보고서 중 그런 게 다수 있을까봐 염려하고 있다. 다만 빅슬립과 같은 기술이 가진 잠재력 자체는 부정하지 않는다.
일반 LLM으로 취약점 분석과 탐지, 가능할까?
빅슬립 등 취약점 분석에 특화된 LLM들만 취약점 연구에 도움이 되는 걸까? 챗GPT나 제미나이 등 일반인들이 손쉽게 접할 수 있는 모델들이라면 어떨까? 답은 “가능하긴 하지만, 인간 확인이 필요하다”이다. 위 빅슬립, 엑스보우, 런시빌의 경우와 동일하다. 그러면 굳이 왜 빅슬립 등 특화된 모델들을 따로 개발한 것일까? 챗GPT를 쓰는 것과 빅슬립을 사용하는 것에는 어떤 차이가 있는 걸까?
위와 같은 질문이 생기는 건 당연하다. 하지만 코드 분석 전문 LLM이 실력적인 면에서 챗GPT나 제미나이를 아득히 앞서는 것으로 알려져 있다. 챗GPT나 제미나이도 취약점 분석이 가능하지만, 분석하고자 하는 코드가 짧아야 정확해진다. 조금이라도 길이가 늘어나면 오류가 나오기 시작한다. 또한 찾아내고자 하는 취약점이 컨텍스트에 대한 의존도가 높으면 높을수록 분석이 어려워진다. 환경적 특성이 많이 반영된 취약점들의 경우도 곧잘 놓친다. 신뢰할 만한 답을 얻어내려면 지켜야 할 것들이 제법 된다는 의미다. 사용하기 편하지 않다는 것. 결과를 신뢰하기도 힘들다는 것.
얼마 전 1979년에 만들어진 체스 프로그램(아타리의 비디오체스)과 최신 LLM인 챗GPT가 체스 시합을 벌인 적 있었다. 누구나 챗GPT가 가볍게 이길 거라고 예상해지만 의외로 비디오체스가 연전연승을 거뒀다. 왜? 챗GPT는 범용성 도구로 언어에 특화된 인공지능이다. 체스를 잘 두기 위해 만들어진 게 아니라는 것이다. 반면 아타리 비디오체스는 오로지 체스만 두기 위해 만들어진 프로그램이다. 특화돼 있다. 그 차이 때문에 챗GPT라는 반짝이는 기술이, 박물관에 있을 법한 프로그램에 연패했다는 건 시사하는 바가 크다. 인공지능이 만능은 아니며, 따라서 전문 분야에 특화된 모델들이 앞으로 계속해서 등장할 것임을 알 수 있다.
실제로 많은 인공지능 전문가들은 다음 인공지능 발전 방향이 ‘세분화’와 ‘전문화’ 쪽이라고 말한다. 사용자들이 범용성에 익숙해지면, 특정 분야에 맞는 질문을 인공지능에 하게 될 것이며, 그러면서 자연히 범용성 인공지능이 전문 지식 측면에 있어서 부족하다는 걸 경험하게 될 것이라고 전문가들은 예측한다. 더더욱 ‘전문화’ 된 LLM을 요구하게 될 것이라는 내용이다. 빅슬립의 ‘최초 버그 리포트’는 ‘자동 취약점 탐지’의 포문을 연 게 아니라, 인공지능 세분화(전문화)의 시작을 알린 것일 수도 있다.
Related Materials
- Google's Big Sleep AI Agent Finds 20 New Open-Source Vulnerabilities - WinBuzzer, 2025년
- Google AI Tool Finds 20 New Vulnerabilities in Open-Source Software - WebProNews, 2025년
- Google's new AI-powered bug hunting tool finds major issues in open-source software - TechRadar Pro, 2025년
- Google's AI tool 'Big Sleep' flags 20 security flaws in open-source software - Hindustan Times, 2025년


![[TE머묾] AI 시대에, 혐오 직업 보유자로 버티기](https://images.unsplash.com/photo-1660212074310-6d7ed176c746?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDMyfHxib3hpbmd8ZW58MHx8fHwxNzcyMDA0ODEwfDA&ixlib=rb-4.1.0&q=80&w=600)

![[단독] 美 NIST, QKD 상용화에 한 발 ‘전진’](https://images.unsplash.com/photo-1733424114804-b7369094b139?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDIxfHxxdWFudHVtfGVufDB8fHx8MTc3MTgyOTY0MXww&ixlib=rb-4.1.0&q=80&w=600)
![[TE머묾] 실패의 굴레에 갇힌 한국](https://images.unsplash.com/photo-1713861808117-8a9a94af4661?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDI2fHxzaW5nYXBvcmUlMjBjb21tdW5pY2F0aW9ufGVufDB8fHx8MTc3MTgyMTU1MXww&ixlib=rb-4.1.0&q=80&w=600)