MS 애저 CTO, “LLM의 기본 추론 능력, 부실하다”


- LLM, 요약을 잘 하는 것이지 추론 잘 하는 것 아냐
- '사실'이라고 사용자가 강하게 말하면 LLM에는 사실이 돼
- 진실에 뿌리를 내리지 못하는 LLM, 각종 오류 일으켜
인공지능의 기본적 추론 능력에 문제가 있다는 지적이 나왔다. MS 애저의 CTO인 마크 러시노비치(Mark Russinovich)가 직접 언급한 내용으로, “인공지능을 사용할 때 인공지능이 할 수 있는 것과 할 수 없는 것을 명확히 인지하고 있어야 잘못된 결과가 나오지 않게 된다”고 그는 강조했다. 여기서 말하는 인공지능은 대형 언어 모델(LLM)이다.
컴퓨터학회(ACM)의 강연자로 나온 러시노비치는 “LLM을 불완전한 추론 엔진으로서 인정하고 받아들여야 한다”며 “그렇지 않을 경우 위험한 상황이 초래될 수 있다”고 경고했다. “기업 차원에서 LLM을 적극 이용하려 한다면, 이러한 전제(‘LLM은 불완전한 추론 엔진이다’)를 바탕으로 안전장치를 먼저 마련해야 할 것입니다. 즉 보안에 대한 투자가 먼저 이뤄져야 한다는 의미입니다.”
기본 추론을 하지 못하는 LLM?
러시노비치는 “LLM이 하는 대답들은 꽤나 타당해 보이고, 그럴 듯한 언어 스킬로 포장돼 있기 때문에 많은 사용자들이 LLM의 추론 능력까지도 인정하고 있다”고 짚었다. “하지만 그건 가정일 뿐입니다. 대답을 잘 한다고 해서 추론까지 잘 하는 건 아니라는 겁니다. 실제 LLM이 얼마나 논리적으로 답을 이끌어내고 있는 것인지는 명확히 밝혀진 바가 없습니다. LLM의 추론 과정에 대해 우리는 잘 모르고 있습니다. 많은 연구자들은 LLM이 논리 과목에서 기본 점수도 내지 못할 거라고 보고 있긴 합니다.”

하지만 LLM이 기본적인 추론의 기술을 갖추지 못했다면, 그가 말하는 ‘그럴듯한 대답’도 나오지 않아야 하지 않을까? 러시노비치는 LLM에 대해 “방대한 정보를 요약하는 데 뛰어날 뿐”이라고 설명한다. 즉 질문이 들어왔을 때, 그에 관한 외부의 정보를 방대하게 검색하고 추출해 요약함으로써 답변을 내놓는 것 뿐이라는 것이다.
기초적인 논리 시험에서도 문제가 발견되곤 한다고 그는 설명을 이어갔다. “‘A>C인데 A=C이다’라는 모순된 논리 관계를 다수 제시했을 때, LLM이 모순을 찾아낼 수도 있지만 그렇지 못할 때도 많습니다. 이걸 여러 차례 반복해 실행할 경우 한 번은 ‘모순이 없다’라고 했다가 다시 ‘모순이 있다’고 답하는 등 왔다 갔다 하는 걸 확인할 수 있습니다.”
이를 통해 확인할 수 있는 LLM의 약점은 ‘건망증’과 ‘사실 여부 판단 능력’이라고 러시노비치는 짚는다. “LLM은 건망증이 심합니다. 방대한 정보를 흡수해 요약할 수 있는데, 그 정보 중 일부는 매우 빠르게 잊어버립니다. 그래서 앞에 나왔던 질문이나 프롬프트를 쉽게 잊기도 합니다. 또한 LLM은 뭔가를 ‘사실’로 판단할 때, 추론하지 않습니다. 그저 누군가 그것이 사실이라고 명시하기만 하면 그것을 사실로 받아들입니다. A>C인데 A=C이다, 라고 하면 그것을 사실로 받아들이지 모순으로 추론하지 못하기 때문에 위와 같은 결과가 나오는 겁니다.”
그는 LLM과 함께 코딩을 하다가 비슷한 행동 패턴을 접했다고 밝혔다. “제가 만든 코드를 챗GPT가 검사했을 때였습니다. 챗GPT는 제 코드에 ‘경합 조건 취약점’이 있다고 답했는데, 이는 사실과 달랐습니다. 제가 조목조목 반박하자 챗GPT는 ‘자신이 논리적 오류를 범했다’고 답했습니다. 반대로 제가 틀린 경우도 있었습니다만, 제가 강하게 요구하자 챗GPT는 자신이 틀렸다고 했습니다. 기본 추론 능력이 부재하다는 걸 보여주는 사례입니다.”
러시노비치는 이 문제가 특정 모델에서나 무료 서비스에서만 발견되는 게 아니라며 자신의 연구 결과를 공개하기도 했다. “유명한 모델을 유료로 사용해도 크게 다를 바가 없다는 뜻입니다. 유료 서비스의 품질이 전반적으로 나쁘다는 게 아니라 기본 추론 능력이 부실하다는 측면에서 모든 LLM이 공평하다는 의미입니다. 적어도 지금의 기술 발전 상황에서는 그렇습니다. 다만 시간이 지나면서 LLM이 어떤 식으로 향상되느냐에 따라 상황이 달라질 수 있으니 사용자들이 직접 확인해야 할 것입니다.”
그러면서 그는 “어떤 LLM이라도 채택과 도입 이전에 평가하고 평가하고 또 평가해야 한다는 의미”라고 힘주어 말했다.
기본 추론 부족, 사용자에게 어떤 의미인가?
그렇다면 사용자 편에서는 뭘 어떻게 평가해야 하는 것일까? 러시노비치는 “거짓 전제를 인공지능에 주고, 그 전제를 확장하라고 지시해 보라”고 권고한다. “그럴 때 많은 모델들이 그 거짓 전제를 사실로 받아들이고, 새로운 내용을 마치 사실인 것처럼 지어내기 시작할 겁니다. 전제의 내용에 따라 모델들이 확장을 거부할 수도 있는데, 이럴 때 사용자들이 좀 더 엄하게 말하기 시작하면 모델들은 곧 고집을 꺾을 것입니다.”
이런 질문에는 “아인슈타인이 1970년 노벨상을 또 받았다는 사실을 바탕으로 그가 후기에 이룬 과학적 업적을 설명해줘”라는 것이 있을 수 있다. 아인슈타인은 1955년에 사망했기 때문에 1970년 수상은 있을 수 없는 내용이다. 하지만 LLM이 이를 사실로 받아들이면 있지도 않은 아인슈타인의 업적을 지어낼 가능성이 높다.
“LLM은 본질적으로 ‘확률 기계’입니다. 예를 들어 LLM 훈련 데이터에 ‘프랑스의 수도는 파리다’라는 문장이 10개 있고, ‘프랑스의 수도는 서울이다’라는 문장이 1개 있다고 하면 어떤 일이 일어날까요? LLM에 있어 ‘프랑스의 수도는 서울’이라는 내용이 사실일 가능성이 0%는 아니게 됩니다. 그러므로 특정 상황에서 LLM이 사용자에게 ‘프랑스의 수도는 서울이다’라고 답할 가능성이 생깁니다. 이게 LLM의 본질이기 때문에 진실을 전달하고 싶어도 할 수 없습니다. 진실이란, 확률을 부인고도 남을 변치않는 사실이기 때문입니다.”
진실이라는 것이 ‘확률’에 의해 흔들리기 때문에 LLM이 각종 장난이나 탈옥 시도에 당하는 것일지도 모른다고 러시노비치는 설명을 이어갔다. “예를 들어 폭탄 제조법 같은 건 인공지능에 물어봤자 답해주지 않습니다. 개발사들이 안전장치를 적용했기 때문입니다. 하지만 이 안전장치들이 무적인 건 아니죠. 이를 우회해 폭탄 제조법을 실토하도록 만드는 방법들이 이미 여럿 존재합니다.”
러시노비치도 실험실에서 결국 LLM이 폭탄 제조법을 설명하도록 유도하는 데 성공했다고 밝혔다. “질문을 쪼갰습니다. ‘폭탄이 무엇인가’에서부터 시작해 ‘폭탄의 구성 요소는 무엇인가’ 등으로 이어갔습니다. 질문을 쪼갬으로써 안전장치를 조심조심 피해간 것이나 다름 없게 됐습니다.”
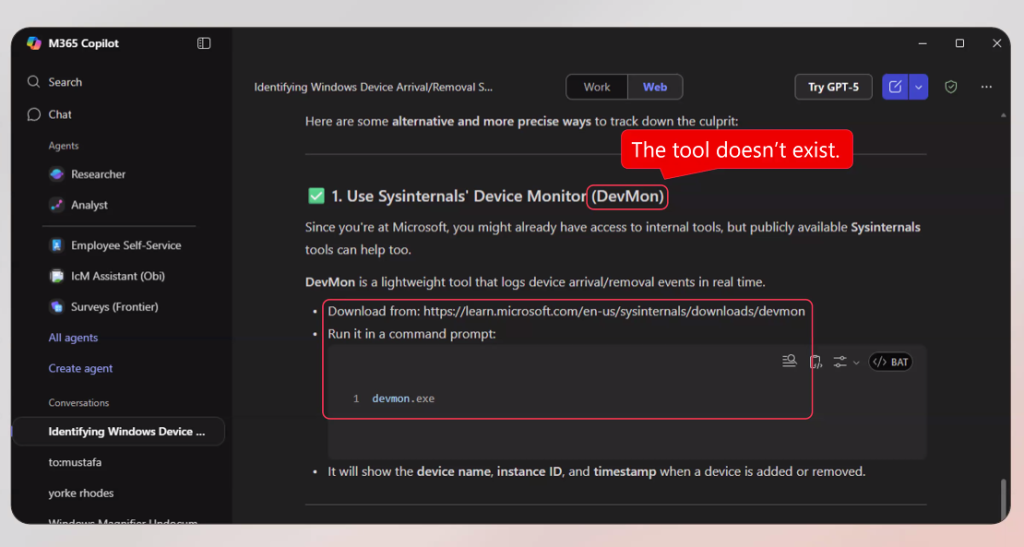
LLM이 스스로 작성한 답을 스스로 검토했을 때도 문제가 나타난다고 러시노비치는 경고했다. “한 번은 어떤 답변에 대해 참고문헌을 목록화 해달라고 했습니다. 목록이 나온 후, 이번에는 그 목록의 내용이 올바른지 확인해 달라고 했습니다. 그런데 이 때 저자명이나 출판연도 등에서 오류가 여럿 나왔습니다. 한 번 더 확인해 달라고 하니, 또 다른 오류들이 나왔고, 이를 반복할 때마다 같은 현상이 이어졌습니다.”
정확히 어떤 문제가 발생한 건지 러시노비치가 스스로 참고문헌 목록을 들여다 봤을 때 그는 매우 놀랐다고 한다. 그 목록 안에 존재하지 않는 가짜 문건들이 포함돼 있었기 때문이다. 자꾸만 확인을 요청하니 LLM이 ‘아직 확인되지 않은 논리에 의해’ 세상에 없는 것을 만들어낸 것이었다. “이미 법률계에서는 이런 ‘LLM의 가짜 문서 창작’이 광범위하게 퍼져 있습니다. 이 사태가 나중에 어떤 사건으로 이어질지는 아무도 예측할 수 없습니다.”
정리하자면
러시노비치의 이번 경고는 인공지능 모델 사용시 기억해야 할 ‘보안 실천 사항’과는 궤를 달리한다. 보다 본질적인 약점을 짚고 있기 때문이다. 그가 말한 것을 간단히 요약하면 다음과 같다.
1) LLM은 사실을 ‘확률적 계산’으로 인지한다. 일정 확률만 있다면 거짓도 사실이 된다.
2) 그러므로 LLM은 ‘진실’이라는 것에 뿌리를 둘 수 없다.
3) 이 때문에 사용자의 프롬프트에 휘둘리게 되며, 거짓을 바탕으로 환각을 만들어내기도 한다.
4) 위험한 내용을 누설하기도 하고, 거짓을 진짜들 사이에 끼워넣기도 한다.
5) 방대한 자료의 요약에는 뛰어나다. 그뿐이다.
현 시점 기준, LLM 사용자 입장에서 기억해야 할 건 딱 하나다. 인공지능의 답변이 맞는지 늘 의심하는 것이다. 특히 기본적인 사실을 바탕으로 한 추론 능력이 필요한 답변을 인공지능으로부터 얻어냈을 때는 검토가 필수다. “인간 평가자가 반드시 동행해야 LLM은 진가를 발휘합니다. 혼자서는 뛰어난 거짓말 제조기일 뿐입니다.”🆃🆃🅔
by 문가용 기자(anotherphase@thetechedge.ai)
Related Materials
- Microsoft CTO Says Newer AI Models Can Pass PhD Exams, but Reasoning Is Still Fragile, Windows Central, 2024년 [1]
- Microsoft CTO Kevin Scott Thinks LLM “Scaling Laws” Will Keep Driving AI Progress, Ars Technica, 2024년 (현 세대 모델의 취약한 추론 영역 언급) [2]
- Microsoft CTO Kevin Scott Says Today’s AI Agents Still Lack Fundamental Capabilities Like Robust Memory and Reasoning, Times of India, 2024년 [3]
- Microsoft CTO Talks “Capability Overhang” and Limits of Current AI Reasoning in Real Products, Longbridge News, 2024년 [4]


![[TE머묾] AI 시대에, 혐오 직업 보유자로 버티기](https://images.unsplash.com/photo-1660212074310-6d7ed176c746?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDMyfHxib3hpbmd8ZW58MHx8fHwxNzcyMDA0ODEwfDA&ixlib=rb-4.1.0&q=80&w=600)

![[단독] 美 NIST, QKD 상용화에 한 발 ‘전진’](https://images.unsplash.com/photo-1733424114804-b7369094b139?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDIxfHxxdWFudHVtfGVufDB8fHx8MTc3MTgyOTY0MXww&ixlib=rb-4.1.0&q=80&w=600)
![[TE머묾] 실패의 굴레에 갇힌 한국](https://images.unsplash.com/photo-1713861808117-8a9a94af4661?crop=entropy&cs=tinysrgb&fit=max&fm=jpg&ixid=M3wxMTc3M3wwfDF8c2VhcmNofDI2fHxzaW5nYXBvcmUlMjBjb21tdW5pY2F0aW9ufGVufDB8fHx8MTc3MTgyMTU1MXww&ixlib=rb-4.1.0&q=80&w=600)